NLP introductory discussion notes
本文最后更新于:3 年前
2.1_Discussion
Attention is all you need
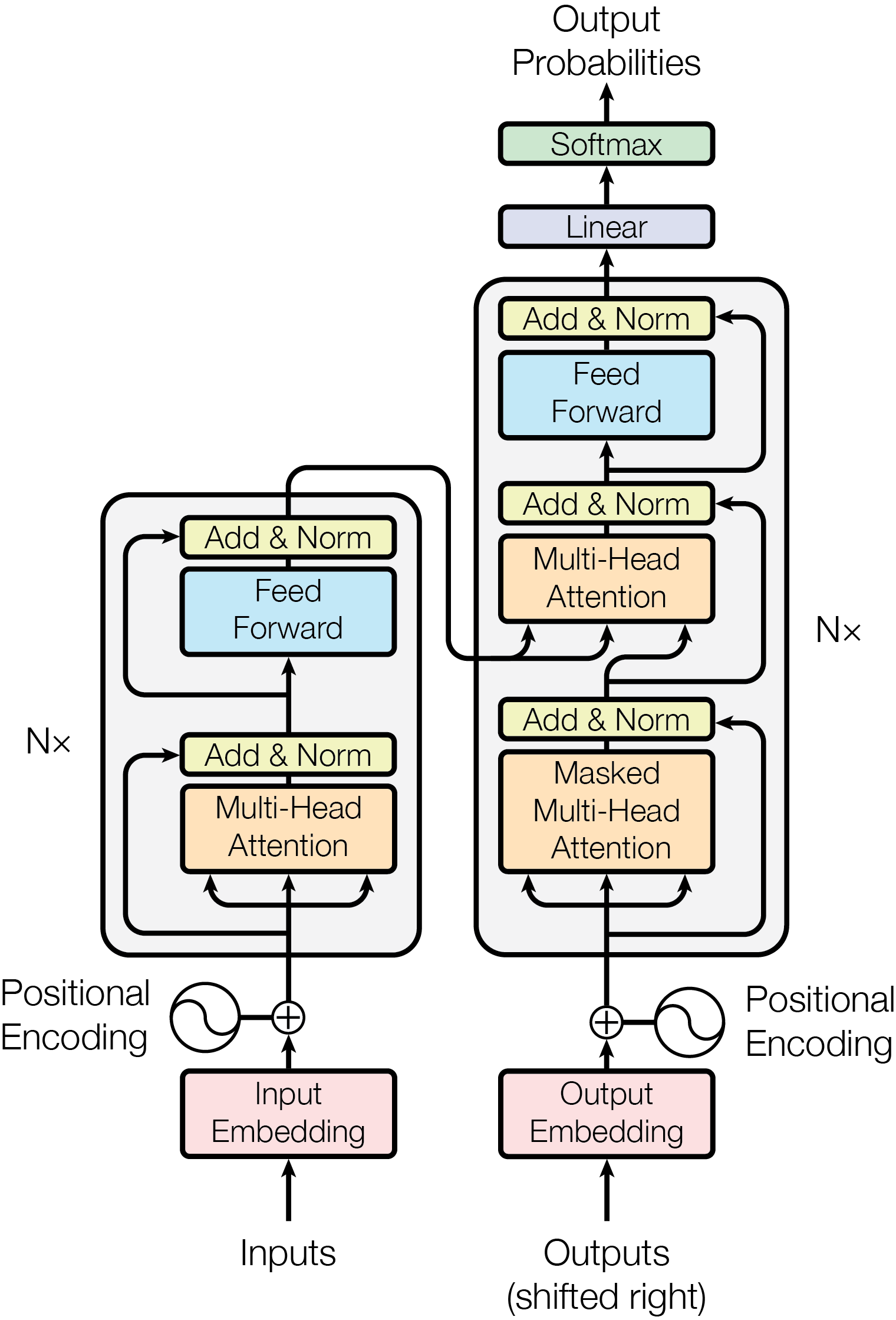
Q, K, V 具体的理解以及在物理中的对应
key-value 为一本字典,query 为用户查询,通过和 key 的匹配程度(不同注意力机制,加性注意力可以处理不等长的情况)去给 value 分配相应的权重。 \[ \begin{array}{|c|c|} \hline \text { 加性模型 } & \alpha\left(q, k_i\right)=v^T \tanh \left(W_k k_i+W_q q\right) \\ \hline \text { 点积模型 } & \alpha\left(q, k_i\right)=q k_i^T \\ \hline \text { 缩放点积模型 } & \alpha\left(q, k_i\right)=q k_i^T / \sqrt{d} \\ \hline \end{array} \] 认知层面:大脑带着目标(query)去理解一段信息时,不同信息片段(key)引起的脑电波(value)不同,注意力会更多地分配给关联程度更高的信息,反之亦然,最后得到的总脑电波在注意力分配下脑电波的加权求和。(做英语阅读文章)
心理层面:在复杂环境下人类有效关注值得注意的点。
量子层面:一个定态量子体系,不同定态波函数(key)对应的能级(value)不同,当其归一的体系状态(query)确定后,通过与不同的定态波函数作内积得到相应的比例分配,则该体系总能量则是按照比例分配下能级的加权求和。
网络中的 Add 的作用?
Add 表示残差连接(Residual Connection)用于防止梯度退化(由于回传通过链式法则,梯度在连乘的作用下趋于 \(0\)),每一层的输出为 \[ \text{LayerNorm} (x+\operatorname{Sublayer}(x)) \] 将模型从学习 \(x\longrightarrow f(x)\) 到学习 \(x\longrightarrow f(x)-x\),深度神经网络在恒等映射上当层数变大时表现不好,该操作将其降为 \(0\) 使得效果变好。
Encoder 中 MASKED 的作用
在编码的时候能看到整个句子,但是在解码的时候预测第 \(t\) 个词时前面的词不能被看到,为 auto-regressive,具体操作为矩阵计算之后把时刻 \(t\) 之后的权重调整为 \(-\infty\),经过 softmax 之后概率趋于 \(0\)。
编码器和解码器的数据传递
编码器的输出作为 key 和 value 、解码器的输出作为 query 进入解码器的第二个多头注意力层。
Multi 的作用
投影 \(h\) 次到不同的子空间,增加权重用来学习,相当于给出 \(h\) 次学习的方式,允许模型在不同的子空间中学习相关的信息。 \[ f(X)=\operatorname{softmax}\left(\dfrac{X W_Q X^T W_K}{\sqrt{d_k}}\right) X W_V \]
使用 Layer-norm 的原因
Batch-norm 是针对每个特征下的所有 batch (样本)正则化
Layer-norm 是针对每个 batch (样本)的所有特征正则化
而语言模型输入的样本长度不一样,如果对每个特征下做正则化,则长短不一不稳定,而对每个样本正则化则长短固定,更稳定。
FFN 的作用
单隐藏层,把 \(512\) 维的向量投影到 \(2048\) 维向量,过一个 ReLU 激活函数,再投影回 \(512\) 维向量,代表语义空间的转换。
总参数
词典大小为 \(V\),记录隐藏层维度为 \(H\),嵌入层参数大小为 \(V\cdot H\),对 \(Q,K,V\) 连接在一起的总投影矩阵大小 \(3H^2\),计算完之后还有一个线性投影 \(H^2\),再连上一个 MLP,参数为 \(4H\cdot H\),前后两个共 \(8H^2\),则总参数量为 \(\boxed{VH+12H^2}\)。
稀疏注意力(Sparse Attention)的分类
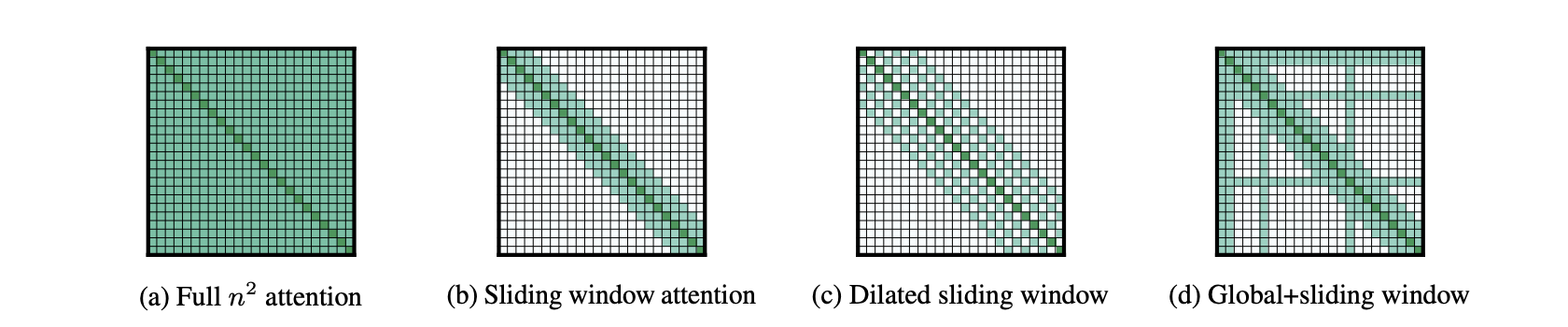
Longformer:处理超长文本,将局部性和全局的影响结合起来
- Sliding window attention (band attention)
- Dilated sliding window attention
- Global+Sliding attention
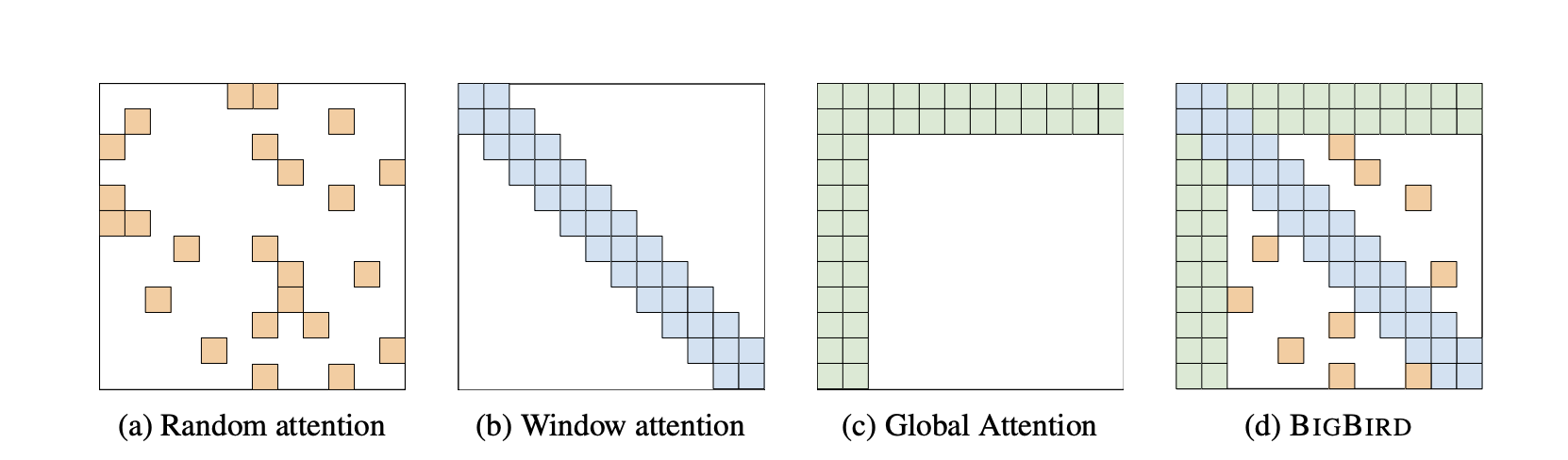
Big Bird:Random attention + Window attention + Global attention
Routing Transformer:使用 K-means 聚类 query 和 keys
Reformer:Multi-round Locality Sensitive Hashing,\(O(n\log n)\)
稀疏性的缺点
- Softmax 无法很好的稀疏化
- 没有严格的理论证明稀疏注意力有足够强的表达能力
BERT
增加一个输出,ELMo 基于双向和基于特征,但使用的架构是循环神经网路 ,GPT 使用 Transformer 架构
迁移学习:在一个比较大的数据集上训练,然后拿到其他地方用(常用在计算机视觉)
[CLS] 有什么作用?
代表 Classification,该词在分类任务能在 Attention 之后对所有词作加权平均,能够更加准确地综合整个句子的信息,方便在分类等任务上进行微调。
位置编码和 Transformer 的不同
使用训练出来的绝对位置编码
Mask 比例
在掩码预测任务中,输入是句子中遮掩掉几个词经过 BERT 网络输出每个字的向量表征。训练中 15% 的词全被 Mask 掉,由于需要微调的时候新输入的数据和之前的数据不同,从而使用 0.8:0.1:0.1 进行替换并做 Ablation study。
2.9 discussion
BERT 后续问题
L 和 h 在小模型和大模型上的依赖关系
eisum() 的作用
爱因斯坦求和,在 model 中叠加位置编码时使用,为
layer-multiplication 和词向量 dot-product
的综合,代码和理解如下
1 | |
\[ \begin{aligned} Q(K)&: \text{batch}\times \text{head} \times \text{layer}\times \text{dimension}\\ P&: \text{layer}\times \text{relative} \times \text{dimension}\\ R&: \text{batch}\times \text{head} \times \text{layer} \times \text{realative} \end{aligned} \]
固定 \(l\) 层,在词向量维度上作内积,得到在每个样本的每个头上的词向量关联四维张量 \[ R_{\text{bhlr}}=\sum_{d}Q_{bhld}P_{lrd} \]
Mask 的打法
1 | |
给 attention_mask 每个维度补上 \(0\),这里主要是 padding
操作。
上述操作在构建输入,预测下一个词的输入
1 | |
上述操作为打 [MASK] 的方法,其中 torch.finfo(dtype).min
代表最小值,在 pytorch 中源码如下
1 | |
Adam 原理
其基于随机梯度下降和指数加权平均数
Adam在 SGD 基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)。
Require: \(\alpha\) : Stepsize
Require: \(\beta_1, \beta_2 \in[0,1)\) : Exponential decay rates for the moment estimates
Require: \(f(\theta)\) : Stochastic objective function with parameters \(\theta\)
Require: \(\theta_0\) : Initial parameter vector
\(m_0 \leftarrow 0\) (Initialize \(1^{\text {st }}\) moment vector)
\(v_0 \leftarrow 0\) (Initialize \(2^{\text {nd }}\) moment vector)
\(t \leftarrow 0\) (Initialize timestep)
while \(\theta_t\) not converged do
\(t \leftarrow t+1\)
\(g_t \leftarrow \nabla_\theta f_t\left(\theta_{t-1}\right)\) (Get gradients w.r.t. stochastic objective at timestep \(t\) )
\(m_t \leftarrow \beta_1 \cdot m_{t-1}+\left(1-\beta_1\right) \cdot g_t\) (Update biased first moment estimate)
\(v_t \leftarrow \beta_2 \cdot v_{t-1}+\left(1-\beta_2\right) \cdot g_t^2\) (Update biased second raw moment estimate)
\(\widehat{m}_t \leftarrow m_t /\left(1-\beta_1^t\right)\) (Compute bias-corrected first moment estimate)
\(\widehat{v}_t \leftarrow v_t /\left(1-\beta_2^t\right)\) (Compute bias-corrected second raw moment estimate)
\(\theta_t \leftarrow \theta_{t-1}-\alpha \cdot \widehat{m}_t /\left(\sqrt{\hat{v}_t}+\epsilon\right)\) (Update parameters)
end while
return \(\theta_t\) (Resulting parameters)